O Trajecta Framework é uma ferramenta poderosa para identificar, monitorar e resolver problemas em sistemas e processos de TI. Ele oferece uma abordagem sistemática para analisar causas, implementar soluções e melhorar continuamente o desempenho das operações empresariais. Abaixo, apresentamos os componentes fundamentais do framework e como eles funcionam em conjunto para garantir eficiência e previsibilidade.
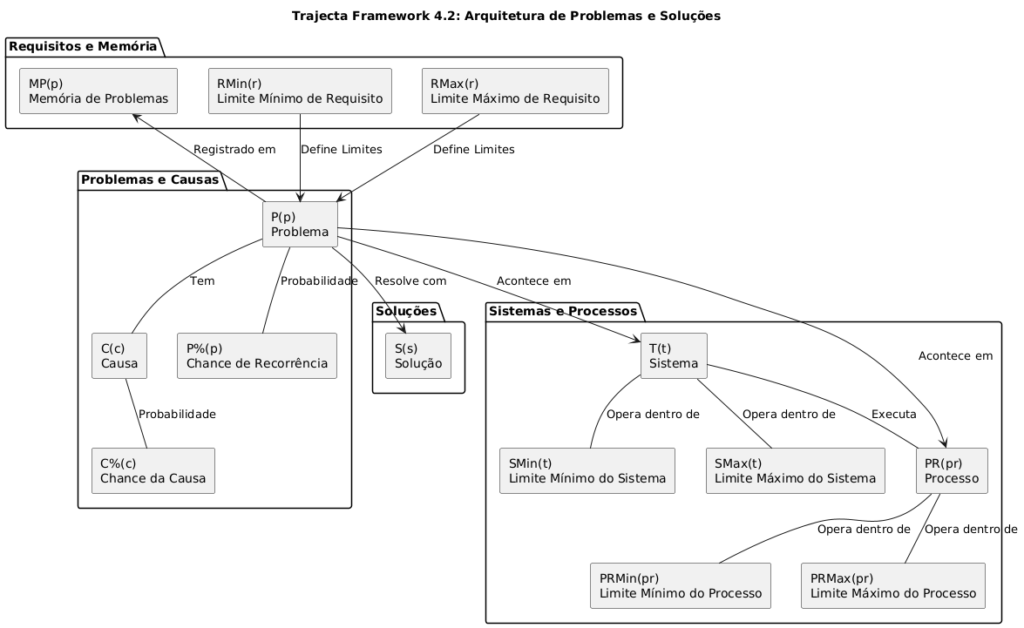
1. Problemas (P(p))
Os problemas são os principais pontos de partida no Trajecta Framework. Cada problema identificado, seja em um sistema ou processo, é representado pela variável P(p).
- P(p): Problema identificado que precisa ser resolvido.
- Exemplo: P(1) pode representar um problema de latência em um sistema de e-commerce.
- P%(p): Percentual de chance de ocorrência ou recorrência do problema P(p).
- Exemplo: P%(1) indica que há 40% de chance do problema de latência voltar a ocorrer no futuro.
2. Causas (C(c))
Cada problema pode ter uma ou mais causas possíveis. As causas são identificadas por C(c), permitindo entender o que gerou o problema.
- C(c): Causa específica de um problema.
- Exemplo: C(1) pode ser “sobrecarga do banco de dados”, enquanto C(2) pode ser “erro de configuração no servidor”.
- C%(c): Percentual de chance de uma causa estar relacionada diretamente ao problema.
- Exemplo: C%(1) indica que há 75% de probabilidade de a sobrecarga ser a causa principal do problema.
3. Soluções (S(s))
As soluções aplicadas ou recomendadas para resolver os problemas são representadas por S(s). Elas são diretamente ligadas a um ou mais problemas identificados.
- S(s): Solução proposta ou implementada para um problema.
- Exemplo: S(1) pode ser “otimização de consultas no banco de dados” para resolver P(1).
4. Sistemas (T(t))
Os sistemas são a infraestrutura tecnológica onde os processos ocorrem. Eles podem ser servidores, aplicativos, bancos de dados, ou qualquer outro tipo de tecnologia que suporte os processos da organização.
- T(t): Sistema específico onde o problema ocorre ou o processo é executado.
- Exemplo: T(1) pode ser um servidor de banco de dados, enquanto T(2) pode ser um servidor de backup.
- SMin(t) e SMax(t): Limites mínimos e máximos de desempenho para um sistema.
- Exemplo: SMin(1) pode ser “30% de uso mínimo de CPU”, e SMax(1) pode ser “85% de uso máximo de CPU”.
5. Processos (PR(pr))
Os processos são as atividades operacionais que ocorrem dentro dos sistemas. Eles são fundamentais para a execução das operações e podem ser monitorados em termos de eficiência e desempenho.
- PR(pr): Processo que está sendo monitorado dentro de um sistema.
- Exemplo: PR(1) pode ser o processo de consulta de inventário no e-commerce, enquanto PR(2) pode ser o processo de backup automatizado.
- PRMin(pr) e PRMax(pr): Limites mínimos e máximos para os processos, garantindo que eles operem de forma eficiente.
- Exemplo: PRMin(1) pode ser “mínimo de 100 transações por hora”, enquanto PRMax(1) pode ser “máximo de 200 transações por hora”.
6. Limites de Requisitos (RMin(r), RMax(r))
Os requisitos são os parâmetros que definem o desempenho aceitável para sistemas e processos. Os limites mínimos e máximos dos requisitos são monitorados para garantir que os processos e sistemas operem dentro de padrões aceitáveis.
- RMin(r): Limite mínimo de um requisito, como tempo de resposta ou desempenho.
- Exemplo: RMin(1) pode ser “tempo de resposta mínimo de 2 segundos”.
- RMax(r): Limite máximo de um requisito.
- Exemplo: RMax(1) pode ser “tempo de resposta máximo de 5 segundos”.
7. Memória de Problemas (MP(p))
A Memória de Problemas (MP) armazena o histórico de todos os problemas, suas causas e soluções aplicadas, permitindo que o sistema aprenda com incidentes passados e se prepare para evitar falhas recorrentes.
- MP(p): Registro do problema na memória, contendo dados sobre suas causas e soluções implementadas.
- Exemplo: MP(1) pode armazenar todo o histórico de P(1), incluindo as causas identificadas, soluções aplicadas e os resultados após a implementação.
8. Percentual de Ocorrência (P%(p))
O framework calcula a probabilidade de um problema ocorrer novamente com base em dados históricos e monitoramento contínuo.
- P%(p): Percentual de chance de recorrência de um problema identificado.
- Exemplo: P%(1) indica que há 40% de chance de o problema de latência voltar a ocorrer no futuro.
9. Percentual de Causa (C%(c))
Além de medir a recorrência de problemas, o framework também calcula o percentual de chance de uma causa específica estar diretamente relacionada ao problema.
- C%(c): Percentual de chance de uma causa estar ligada ao problema.
- Exemplo: C%(1) indica que há 75% de chance de a sobrecarga no banco de dados ser a principal causa de P(1).
Como o Trajecta Framework Funciona
O Trajecta Framework 4.2 opera de forma modular, conectando problemas a causas, soluções e sistemas, enquanto monitora os processos para garantir eficiência. O framework:
- Identifica problemas (P(p)): Monitorando sistemas e processos, detecta problemas operacionais e define seu impacto.
- Analisa as causas (C(c)): Determina as causas potenciais dos problemas e calcula a probabilidade de cada uma ser a principal responsável.
- Aplica soluções (S(s)): Propõe e implementa soluções adequadas, ligando diretamente as soluções aos problemas e causas.
- Monitora sistemas e processos (T(t), PR(pr)): Garante que os sistemas e processos operem dentro dos limites aceitáveis de desempenho.
- Armazena dados para aprendizagem (MP(p)): Utiliza a memória de problemas para aprender com falhas passadas, prevenindo recorrências e ajustando as previsões para problemas futuros.
Exemplo de Aplicação:
Problema de Latência em Transações de E-commerce
- P(1): Latência nas transações de e-commerce.
- C(1): Sobrecarga no banco de dados (T(1)).
- C%(1): 75% de chance de ser a principal causa.
- S(1): Otimização de consultas SQL.
- T(1): Sistema de banco de dados que processa as transações.
- PR(1): Processo de consulta de inventário e finalização de pedidos.
- RMin(1) e RMax(1): Limites de tempo de resposta.
- RMin(1): Tempo mínimo de 2 segundos.
- RMax(1): Tempo máximo de 5 segundos.
- SMin(1) e SMax(1): Limites de uso de CPU no banco de dados.
- SMin(1): 30% de uso de CPU.
- SMax(1): 85% de uso de CPU.
- MP(1): Registro do problema de latência e suas soluções na memória.
- P%(1): 40% de chance de recorrência do problema.
Está na hora de criar! O Trajecta Framework permite que sua empresa identifique, resolva e previna problemas de forma proativa, garantindo que sistemas e processos operem dentro dos padrões de desempenho estabelecidos e com o máximo de eficiência.
Deixe um comentário